

摘要:篩選重點專利是專利分析的重要工作內容,需要采用既準確又便捷的重點專利篩選模型。文章從選擇構建模型所采用的指標出發,對指標進行修正以提高其可獲得性和代表性;隨后提出以單個指標數值與指標中位數相減的指標處理方法,提升不同專利之間的差異性;最后提出構建標準尺度的指標整合方法,從而統一指標量綱和數量級,提升了計算專利價值常用的權重系數線性加和法的可操作性,并為指標擴展預留空間。根據實踐驗證結果,該重點專利篩選模型能夠從高噪音專利樣本中快速、客觀地篩選出重點專利,具有良好的通用性和靈活性。
關鍵詞:專利分析;重點專利;專利篩選模型
作者簡介:王錚(1985—),男,河北保定人,碩士,高級知識產權師,研究方向:知識產權分析運用。
基于專利評價指標的分析方法是傳統專利分析方法的延伸,能夠從多維度探究專利數據背后所蘊含的豐富信息[1]。該方法的實施依賴于對重點專利的有效篩選。此處所稱重點專利,指的是綜合考慮專利的技術、經濟和法律屬性,能夠體現專利對于其所屬技術領域的引領性、能夠反映其申請人的專利布局意圖、在業界獲得廣泛關注的專利。
專利分析師希望既準確又便捷地篩選重點專利,但是在實踐操作中,增加指標種類以提高模型精度往往伴隨著工作量的巨大增加,并且受限于專利數據庫收錄不全面,或者指標需要經過計算方可用于上述模型中,造成個別指標難以方便獲取。另一方面,專利分析師需要快速地從海量數據中篩選出重點專利,以期盡快為后續工作指明重點研究方向并縮短工期。因此,希望重點專利篩選模型在保證可靠性的基礎上能夠進一步實現較高的自動化程度。
本文對重點專利模型展開研究,通過同時對專利價值的指標選取和計算方法進行優化,從而提供一種兼顧精度與速度的改進的模型體系。
一、指標的選擇
現有技術中篩選重點專利多采用指標權重線性加和法,計算公式如式(1)所示[2]:

此方法的基本原理是,將各指標的值(Ci)與其權重(Ai)相乘,各乘積加和以算出分值P作為專利價值評分,P值越大則專利越重要。
由此可見,建立重點專利篩選模型的第一步是選擇適宜的體現專利價值的指標。業界對此已有研究[3-5] ,但這些指標的獲取和應用往往有著嚴苛的適用條件,難以直接應用于模型計算之中。本文旨在提供一種兼顧精度與速度的改進的模型體系,對于指標的選擇和計算處理應滿足以下三個條件:
(1)單個指標定量可算:指標數據可從專利數據庫導出數據中直接獲取或僅需簡單計算,避免過多人工參與以提高效率。
(2)指標取值差異 明顯:對指標數據進行預處理,以使重點專利與非重點專利的差異更加明顯。
(3)不同指標量級一致:對多個指標的量綱和數量級進行歸一化處理,使之可以直接線性加和,確保模型的可操作性,保持引入更多指標的靈活性。
以之為前提,進一步考慮專利的本質屬性,則指標優選覆蓋技術、法律和商業這三個維度。進一步地,與針對特定技術點的學術研究不同,對于常規的基于大數據的專利分析,排斥需要通過復雜計算方可獲得數據的指標;另外,專利在統計方面的另一個特點是存在“專利家族”①的概念,對于特定的指標而言,以“專利家族”為對象還是以“單件專利”為對象,會對該指標的取值造成影響,進而引入了額外的計算量乃至造成客觀上無法計算的局面,故盡量降低額外的計算量也是篩選指標時的考慮因素。
基于上述考慮,從指標對于專利的代表性、指標數據獲取難易等角度出發,本文選取被引用次數、引用次數、權利要求項數和家族成員數四個指標作為基本指標,并對其進行修正,參見表 1.

被引用次數是可以從數據庫中直接導出的指標②,是反映專利技術價值的重要指標。需要修正的是,第三人引用 ③受到語言限制、數據庫信息來源等的影響,導致同一專利家族的不同成員單獨的被引用次數可能不同,因此應當采用專利家族總的被引用次數來統計。被申請人④主動引用的文獻顯然與其發明的技術具有密切關聯,故引用次數的技術代表性較強,該指標同樣可從數據庫中直接導出,其同樣采用專利家族總的引用次數來統計。
權利要求項數一般可從市面上主流數據庫直接導出⑤,代表著申請人所請求保護和被批準予以保護的技術方案數量,是申請人和專利行政機關對該專利態度的直接體現,代表了專利的法律屬性。對于不同家族成員的權利要求項數分歧,可以以家族最早授權成員為準;家族無授權則以最早公開成員為準,或以分析目標地域的家族成員為準。
專利家族成員數反映了申請人的專利布局地域態勢,是專利經濟屬性的代表。該指標一般可從市面上主流數據庫直接導出,只是對于同一申請號下各公開版本不重復計數。
除了上述四個指標外,還可以考慮諸如申請人/發明人數(技術屬性)、專利權維持時間與專利授權周期(法律屬性)、質押許可訴訟次數(市場屬性)等,但其難點在于數據庫是否準確完整地收錄了相關信息,包括申請人變更情況、各成員授權情況、質押許可訴訟情況等,并且這些數據需要經過一定的計算方可轉化為模型中所用的指標數據, 與本文“避免過多人工參與以提高效率”的宗旨相偏離。這些指標以及其他任何類似指標,盡管并非優選,但在條件允許的情況下同樣可以納入本文的模型之中,并且具有實際的可操作性,這是本文模型的優點所在,不同指標的整合與統一方法是后文研究的內容。
二、指標的處理
對于一個專利樣本集合,每個專利均以若干指標為標準進行量化取值,即專利價值;對于每一個指標,希望通過一定的數學處理來凸顯其與整體趨勢的差異性,從而進一步提高模型的精度。
一種操作思路是,將一個指標在特定專利上的取值(下稱特定值)與該指標在全部專利樣本上的“趨勢值”相減,如式(2)所示:
指標計算值 =指標特定值 - 樣本中該指標的“趨勢值”(2)
特定值與趨勢值接近,則結果接近0.減弱乃至消除該指標對于該專利價值的影響;特定值大于趨勢值,則結果為正,差異越大則正值越大;特定值小于趨勢值則結果為負,與正值的情況產生顯著區分,進一步拉低“低下”專利指標對于專利價值的影響。另外,從量綱上講,減法不改變量綱(不存在除法處理后量綱為“1”的情況),以便在后續處理中實現不同類型和不同數量級的專利指標的整合。
那么問題聚焦于對于“趨勢值”的選擇。平均值是常見的反映樣本整體情況的指標,但是對于重點專利篩選模型而言可能并不適宜。圖1展示了專利樣本 ⑥中各專利對應表1各指標的分布情況:
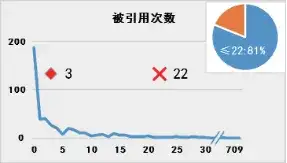
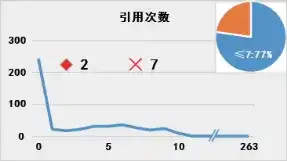
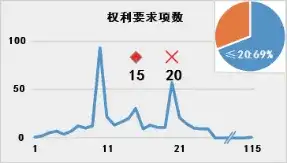
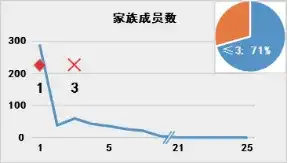
圖1 專利數量(縱軸)相對于專利指標值(橫軸)的分布
(注:菱形◇表示中位數,叉號× 表示平均數;右上角餅圖中百分比表示指標值在平均數以下專利占比)
由圖可見,表1所示指標的專利數量分布存在明顯的特征:專利數量并非隨指標值呈現正態分布,而是存在明顯的聚集性,并且這種聚集性在指標數值的低位更加明顯。聚集性是基于專利數量的累積而展現的,適宜的“趨勢值”也應當反映出這種數量的集中。
采用平均值作為“趨勢值”是不適宜的。圖1中各指標特定值在平均值以下的專利占比均超過2/3.以“被引用次數”為例,被引用次數在平均值22次以下的專利高達81%,因此高被引專利屬于稀有的“黑天鵝”,以平均值作為“趨勢值”并不一定影響這些“黑天鵝”對于專利價值得分的貢獻趨勢,但是對于特定值位于平均數與中位數之間的、具有一定潛力的專利而言,依照式(2),則其對于專利價值得分的貢獻為負值,即完全否定了這些專利的貢獻,而其中不乏具有重要價值的周邊專利。特別是對于聚集性較為分散的特征如“權利要求項數”而言,以一篇18項權利要求的專利為例,其與中位數15項的差距為3.該專利的權利要求項數已經超過了過半數的樣本,則“3”這個正值反映出該專利相對于“普羅大眾”而言存在一定優勢;如果以平均數20為準,則“-2”的結果是將該專利完全歸入“普羅大眾”之中。單個指標無法對處于臨界值的專利進行有效篩選,則多個專利指標組合起來會進一步放大這種偏差,最終導致以平均數為“趨勢值”的專利價值得分只能區分最佳者與最差者,顆粒度過于粗糙,無法用于建立高精度模型。
相對于平均數而言,中位數將是一個更適宜的“趨勢值”,它可以彌補平均數在偏態分布中的不足之處[6]。圖1中示出各指標的中位數(菱形◇) 與平均數(叉號×)在專利數量分布中的位置,可見中位數與專利密集聚集的分布數量更加接近,以之為“趨勢值”可以將絕大部分專利與特征值較為突出的專利區分開來,并將這種差異放大。基于此可將式(2)進一步修正為式(3):
指標計算值=指標特定值 - 樣本中該指標的中位數(3)
以“被引用次數”為例,樣本中絕大多數專利家族被引次數在中位數3次以下,則對于僅被引用一兩次的低被引專利而言,其指標計算值為負數,從而拉低專利價值得分;被引用次數達到700余次的高被引專利,其指標計算值為正,并且其對專利價值得分的貢獻可視為“增加”了相對于低被引專利的“負數”的絕對值,即起到放大效果。
值得一提的是,中位數在Excel、PowerBI中均有對應函數可以直接計算得出,方便分析人員進行數據處理。
三、指標的整合
通過前文的分析,確定了可以作為重點專利篩選模型所用的指標及單個指標的處理方法,接下來的問題是如何將多個指標組合起來以獲得重點專利的分值。
式(3)在實際操作 中存在兩個問題。一是不同的指標其量綱往往不同,例如權利要求數為“項”,而被引用次數為“次”,不同量綱的值直接加和是不合理的,并且這種不合理也無法通過無量綱的系數來修正。二是不同指標的數值的數量級可能存在極大差異,例如被引用次數可能高達幾百次,而家族成員數則不超過50.指標值直接加和顯然會導致“多指標體系”明顯偏向于絕對值最高的指標,從而淪為“單指標體系”。理論上確實可以通過對不同的指標提供不同的權重系數來平衡各指標絕對值數量級的差異,但這違背了權重系數“用來平衡不同指標對總分值貢獻程度”的基本用途,變成了對于單個指標自身取值的調整,并且不同的專利樣本其絕對值最大的指標并不固定(盡管多為被引用次數)、最大者的數值亦不固定,實際上也不可能提供具有普適性的權重系數。
為了解決上述問題,以使模型具有良好的可操作性(特別是提高其自動化程度),需要構建一個“尺度”,其在邏輯上能夠衡量在特定指標上單篇專利取值相對于樣本整體所處的位置,即以“相對值”替代“絕對值”,來消除量綱和數量級(量級)的差異,同時其應當可以通過相對簡單的計算實現、確保可操作性。
對于特定指標分析其數據構成,可以繪制出圖 2:
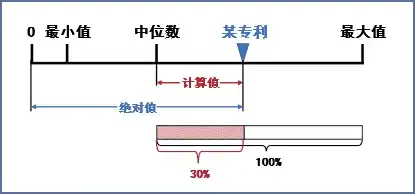
圖2 特定指標的數據構成
基于某專利(倒三角▽)被引用次數的絕對值,以及樣本的中位數,根據式(3)可以得出其計算值。同理,樣本中被引用次數最大的專利亦可得出其“最大值”。該“最大值”顯然是圖中從中位數到最大值之間的一段“距離”,將其視作100%,那么某專利的計算值相當于“占據”了該“100%”中的一定比例(例如30%)。推而廣之,對于樣本中絕對值超過中位數的專利而言,其計算值都可以折算為以最大計算值為100%的相對份額,顯然該份額的最小值是0%、最大值是100%⑦,其公式可以寫作式(4):
指標相對值=(特定值 - 中位數)÷(最大特定值 - 中位數)×100% (4)
式(4)中,首先是通過將相同指標的計算值與最大計算值相除而將結果量綱歸一,其次是將離散的計算值按照統一尺度折算為百分比,從而消除了不同指標的數量級的差異。基于此,可以對式(4)進行修改而得到式(5):
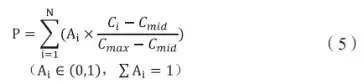
式(5)中,Ci是某專利的第i個指標的絕對值,Cmid、Cmax、Ai分別代表樣本中第i個指標的中位數和最大值及其權重,對于N個指標線性加和算得分值P即專利價值。
對于權重系數Ai,其總和為1.意味著將全部用于計算的指標視為一個整體,利用取值范圍為(0.1 )的權重系數調整各指標對于P值的貢獻度,使得權重系數不再受到指標在專利樣本中實際數值范圍等變化因素的影響。
結合前文確定的四個指標:被引用次數、引用次數、權利要求項數和專利家族成員數,可以計算每一篇專利的分值,分值高者認為更加重要。基于式(5)的一個顯著優點在于,可以根據實際情況靈活地增刪指標,例如本文基于獲得難度而忽略了專利權維持時間、專利授權周期等指標,如果這些指標的數據可以獲得,則依然可以將其納入式(5)中,進一步提高P值的客觀性。
四、驗證與討論
作為驗證,根據式(5)計算專利樣本中各專利的專利價值,取其前十名列于表2中 ⑧。需要說明的是,本文未對專利樣本進行人工閱讀去噪,目的在于檢驗模型是否可以適用于對高噪音樣本中重點專利的快速篩選。
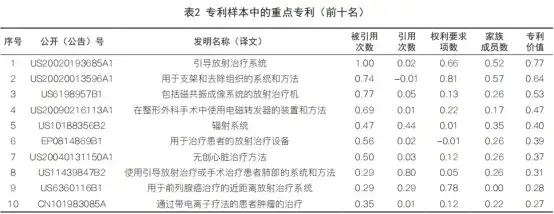
排名第一的US20020193685A1和第二的US2 0020013596A1均是美國瓦里安(VARIAN)的專利,其對應家族分別被引用700余次和500余次,并在美國、加拿大、澳大利亞、歐洲、日本等進行布局,兩者屬于同一技術路徑,代表了該申請人在放療圖像引導方向的技術方向。
排名第五的US10188356B2同樣是美國瓦里安的專利,其涉及同軸共面型圖像引導放療設備。該專利屬于“集大成者”,是該申請人在技術發展早期為了搶占市場而布局的關鍵專利,盡管該專利被引用次數較低,但是其基于美國信息披露聲明(Information Disclosure Statement,IDS)制度而披露了大量相關專利,專利引用次數高,進而推高了專利價值評分。
排 名 第 六 的EP0814869B1是 英 國 醫 科 達(ELEKTA)的專利,其提供一種同軸共面型CT引導直線加速器,采用“寬射束”的射線束使患者支架至少部分地容納在治療裝置,從而縮小設備體積并提高治療精度。該專利在美、日、歐(英、德)進行布局,代表了該類型設備的發展趨勢和該申請人的技術路線。
其他專利不再逐一分析。總結可見,利用式(5)確實可以篩選出專利樣本技術領域中重要申請人的重要專利,盡管這些專利在各個指標上的特點各異,但式(5)能夠對專利的價值進行綜合性的評價,使結果更加客觀,避免了單一指標絕對值過高而“掩蓋”其他重點專利的情況;相關數據獲得容易、計算處理簡單,具有良好的操作性。
五、結語
利用本文的重點專利篩選模型,能夠快速、客觀地篩選出專利樣本中的重點專利。該模型具有良好的通用性和靈活性,不受專利樣本技術領域或其他因素的限制,在任何場景下均可適用,根據數據源情況還可以自由地增加專利指標,同時提供可以人工調整的權重系數以實現對于模型的微調,從而進一步提高模型精度。
特別值得一提的是,隨著Microsoft PowerBI等基于大數據的商業情報分析軟件(BI軟件)在專利分析中的應用,通過將本文的模型嵌入到BI軟件的數據模型之中,可實現重點專利篩選結果與專利數據庫導出數據(即原始數據)的耦合,方便指標數據的獲取,以及實現重點專利與其他專利因素(例如地域、時間等)的耦合,提升分析數據的深度和廣度,有助于提升專利分析效率和提高專利分析質量。
(致 謝: 衷 心 感 謝 唐 躍 強 老 師 對 本 文 的指導。)
注釋:
① 為了方便理解,本文采用德溫特定義的簡單專利家族,即優先權完全一致的各成員構成的專利家族。
② 筆者以智慧芽 Ⅲ專利數據庫為例,其導出項包括“簡單同族被引用專利總數”。
③ 第三人的引用泛指在后專利申請人以外的組織機構對于在前專利的引用,例如在專利實審、無效、訴訟階段被審查員(合議組)、法庭、相關當事人引用。顯然這些引用的目的與證明技術事實密切相關。
④ 專利授權后,申請人被稱為專利權人。本文統一采用申請人這一稱謂。
⑤ 智慧芽 Ⅲ僅對高級用戶開放導出權利要求項數的功能,但是可以通過導出的權利要求文本簡單地計算出該指標。
⑥ 此處筆者采用大型醫療設備領域的相關數據,檢索數據庫為智慧芽™,檢索時間為2023年 4月。
⑦ 如前分析,對于專利的特定指標絕對值小于中位數的情況,該指標絕對值為負,亦可折算為相對100%的“負數份額”,視為該指標對該專利價值的貢獻為負。
⑧ 各指標權重系數為:被引用次數0.6、引用次數0.2、權利要求項數0.1、專利家族成員數0.1.
參考文獻:
[1] 國家知識產權局學術委員會. 專利分析實務手冊[M]. 第 2版. 北京: 知識產權出版社, 2021:234.
[2] 馬天旗. 專利分析:方法、圖表解讀與情報挖掘[M]. 第 1版. 北京: 知識產權出版社, 2015:164.
[3] Lanjouw J O, Schankerman M. The quality of ideas: measuring innovation with multiple indicators[J]. NBER Working Papers, 1999:1-35.
[4] Lanjouw J O, Schankerman M . Patent Quality and Research Productivity: Measuring Innovation with Multiple Indicators[J]. Economic Journal, 2004(114):441-465.
[5] Mariagrazia S, Dernis H, Criscuolo C. Measuring patent quality: Indicators of technological and economic value[J]. OECD Science, Technology and Industry Working Papers, No.2013/03. 2013: 1-69.
[6]張吉吉. 平均數、中位數和眾數的意義分別是什么? [EB/OL]. (2018-07-25) [2023-08-17]. https://www.zhihu.com/question/286260644.
中企檢測認證網提供iso體系認證機構查詢,檢驗檢測、認證認可、資質資格、計量校準、知識產權貫標一站式行業企業服務平臺。中企檢測認證網為檢測行業相關檢驗、檢測、認證、計量、校準機構,儀器設備、耗材、配件、試劑、標準品供應商,法規咨詢、標準服務、實驗室軟件提供商提供包括品牌宣傳、產品展示、技術交流、新品推薦等全方位推廣服務。這個問題就給大家解答到這里了,如還需要了解更多專業性問題可以撥打中企檢測認證網在線客服13550333441。為您提供全面檢測、認證、商標、專利、知識產權、版權法律法規知識資訊,包括商標注冊、食品檢測、第三方檢測機構、網絡信息技術檢測、環境檢測、管理體系認證、服務體系認證、產品認證、版權登記、專利申請、知識產權、檢測法、認證標準等信息,中企檢測認證網為檢測認證商標專利從業者提供多種檢測、認證、知識產權、版權、商標、專利的轉讓代理查詢法律法規,咨詢輔導等知識。
本文內容整合網站:中國政府網、百度百科、搜狗百科、360百科、最高人民法院、知乎、市場監督總局 、國家知識產權局、國家商標局
免責聲明:本文部分內容根據網絡信息整理,文章版權歸原作者所有。向原作者致敬!發布旨在積善利他,如涉及作品內容、版權和其它問題,請跟我們聯系刪除并致歉!



